
Google、AI学習データを最大1万分の1に削減する新技術、少ないデータで人間並みの精度を実現
- 2025/8/9 19:49
- 話題
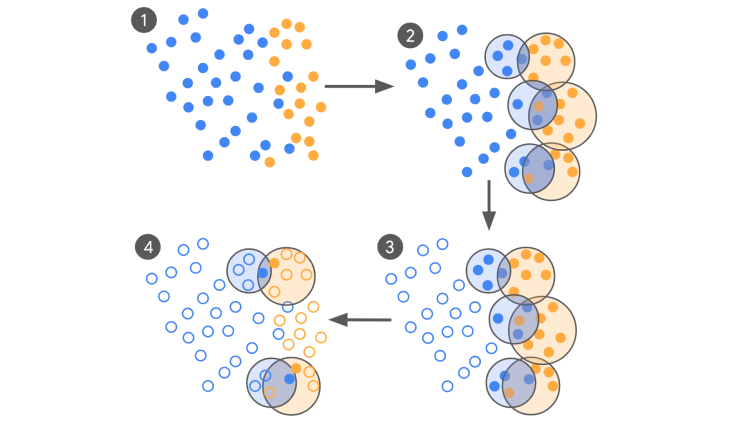
■従来10万件必要だった学習をわずか250件で可能に
Googleは8月7日、大規模なAIモデルの学習(微調整)に必要なデータ量を最大1万分の1まで減らせる新しい方法を発表した。この技術は、広告が安全かどうかを判断する作業を想定して開発されたもので、人間の専門家と同じ水準の判断精度を保ちながら、従来10万件必要だったデータをわずか250~450件にまで減らすことに成功した。
ポイントは「アクティブラーニング」と呼ばれる仕組みを使ったデータの選び方にある。まず、AIが大量のデータをざっくり分類し、その中から「判断が難しい境界線上の事例」だけを抜き出す。その重要な事例にだけ専門家が正しい答えをつけ、AIがそのデータを使って繰り返し学習する。評価には、複数の専門家がどれだけ同じ判断をしているかを示す「コーエンのカッパ値」という指標を採用し、高い信頼性(0.8以上)を実現した。
実験では、特に大きなAIモデル(3.25Bパラメータ)で効果が大きかった。例えば、クラウドソーシングで集めた10万件のデータではカッパ値0.23だったのに対し、専門家が付けた450件のデータでは0.38に上昇。データ量を99.5%減らしつつ、精度を65%高めた。一方、小さなモデルでは効果が限定的で、モデルの規模によって相性があることも分かった。
最大のメリットは、判断基準が変わったときの素早い対応だ。従来は全データを使って再学習する必要があったが、この方法なら迷いやすい事例だけに絞って少量のデータで更新できる。広告審査のように解釈が分かれる仕事に向いており、専門家の判断基準が変化しても柔軟に適応できる。今後は、高品質なデータを継続的に確保する仕組みづくりが課題となる。(情報提供:日本インタビュ新聞社・株式投資情報編集部)
関連記事






ピックアップ記事
-
2025/12/24
南鳥島沖EEZ海域6000mで世界初、レアアース泥採鉱システムを検証■「ちきゅう」を投入、令和8年1月から2月にかけて実証 内閣府戦略的イノベーション創造プログラム… -

2025/12/24
日本政府、人工知能(AI)基本計画を閣議決定、首相主導・全閣僚参画でAI戦略推進■人工知能基本計画が始動、利活用から開発への循環促進、世界最先端のAI国家を標榜 政府は12月2… -

2025/12/23
国内造船業がV字回復、増収増益続く一方で中韓勢と競争激化■222社分析で売上2兆円台復帰、利益は1,435億580万円へ倍増 東京商工リサーチ(TSR)…











